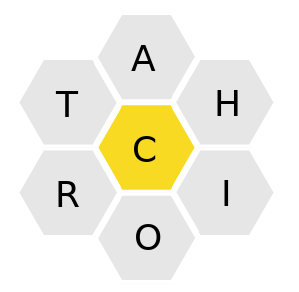
The online game Spelling Bee from the New York Times is extremely popular these days and quite addictive. Given seven letters arranged in a grid of hexagons, form as many words as you can. Each word must be four letters or longer and contain the center letter, and letters may repeat.
For example, in the puzzle shown, you can form words like TACO and CHITCHAT because they contain only letters from the grid including the central C. Some invalid words are CAT (3 letters is too short), RIOT (it’s missing the center letter, C), and TOUCH (the letter O isn’t in the grid).
Let’s sharpen your Linux command-line skills by generating and solving these spelling puzzles using a few clever commands. We’ll also analyze the results and even print hints for other puzzle solvers.
Getting started
To generate and solve puzzles, you’ll need a Linux dictionary: a text file of words, one word per line. Most Linux distros include the file /usr/share/dict/words which contains over 100,000 words in this format:
$ wc -l /usr/share/dict/words 102305 /usr/share/dict/words
Otherwise, you can download an even larger dictionary (over 450,000 words) from GitHub.
Generating a puzzle and solution
Generating a puzzle doesn’t require any Linux commands: just pick any seven letters and designate one of them as the central letter. Let’s use the preceding puzzle, which features the letters A, H, I, O, R, T, and a central C.
To generate a solution to this puzzle, you’ll need to identify words that contain a C embedded within the letters in the set, as in this regular expression:
/^[achiort]*c[achiort]*$/
The following one-line awk command selects dictionary words that match this expression and are at least four characters long:
$ awk "/^[achiort]*c[achiort]*$/ && length >= 4" /usr/share/dict/words acacia achoo actor arch archaic arctic arthritic ...and so on...
To view this long list of words more conveniently, pipe the output through the column command:
$ awk "/^[achiort]*c[achiort]*$/ && length >= 4" /usr/share/dict/words | column acacia cahoot chart cocoa ricotta achoo carat chat cohort roach actor carrot chic coot rococo arch cart chichi critic tacit archaic cataract chit croci taco arctic catarrh chitchat crotch tact arthritic catch choir hatch tactic attach cathartic circa hitch thatch attic chair citric hooch thoracic attract chaotic coach hootch torch cacao char coat itch tract cacti chariot cocci rich tractor
The preceding command works only for our particular puzzle. To generate any puzzle’s solution, turn the command into a shell script with two arguments: the central letter (argument $1), and the remaining six letters (argument $2). So instead of ahiortc you’d write $2$1.
#!/bin/bash awk "/^[$2$1]*$1[$2$1]*$/ && length >= 4" /usr/share/dict/words
Add some basic error-checking, and you have a complete script that solves puzzles. Call it spellingbee.
#!/bin/bash DICTIONARY=/usr/share/dict/words # Variable to support other dictionary files if [ $# -ne 2 ]; then >&2 echo "Usage: $0 center_letter six_other_letters" >&2 echo "Example: $0 g abcdef" exit 1 fi awk "/^[$2$1]*$1[$2$1]*$/ && length >= 4" "$DICTIONARY"
Run the script to print all valid words in a solution. Pipe its output to wc -l to count how many words the solution contains (in this case, 60 words).
$ ./spellingbee c ahiort acacia achoo actor ...and so on... $ ./spellingbee c ahiort | wc -l 60
Disclaimer: In case it isn’t obvious, you could also run the spellingbee script to cheat at the New York Times game. Don’t be naughty though. You’re only cheating yourself. 🙂
Playing the game
Now, try to discover words within your seven letters according to the rules. When you’ve found a word, such as baggage, simply use grep -iw to search for it in the output of the spellingbee script. If grep prints the word, it’s in the solution. Otherwise there’s no output.
$ ./spellingbee c ahiort | grep -iw chitchat chitchat $ ./spellingbee c ahiort | grep -iw cat (no output)
To keep track of your guesses, append the results to a file, guesses, using redirection. Incorrect guesses will not append anything to the file.
$ ./spellingbee c ahiort | grep -iw chitchat >> guesses $ ./spellingbee c ahiort | grep -iw cat >> guesses $ ./spellingbee c taco | grep -iw chitchat >> guesses $ cat guesses chitchat taco
Scoring
The object of Spelling Bee is to score points. Each four-letter word is worth 1 point, and a longer word with N letters is worth N points. (There are more scoring rules, but let’s stop there for now.) Write an awk program that adds up the points:
# total-points.awk
BEGIN {total=0} # Initialize total to 0
length($0) == 4 {total+=1} # 4 letter words are worth 1 point
length($0) > 4 {total+=length($0)} # Words of length N>4 are worth N points
END {print total} # When finished, print the total
To count the maximum number of points in the game, pipe the full solution to your awk program. Our puzzle is worth 297 points in total:
$ ./spellingbee c ahiort | awk -f total-points.awk 297
To calculate your own score at any time, apply the same technique, but read the guesses file instead of the output of spellingbee.
$ cat guesses chitchat taco $ awk -f total-points.awk guesses 9
Pangrams
Spelling Bee has another kind of word that is worth extra points. It’s called a pangram, and it contains all seven letters at least once, in any order. You can detect pangrams in a puzzle solution by matching seven patterns in sequence, one for each letter. An awk expression for our specific puzzle would be:
/c/ && /a/ && /h/ && /i/ && /o/ && /r/ && /t/
To generalize this method, use sed to generate the above expression as a string and pass it on the command line to awk. Start with the last six letters (ahiort, but not c) and tell sed to print them surrounded by slashes (//) and preceded by a double ampersand (&&). (To avoid escaping the slashes, I use @ as sed’s delimiter character.)
$ echo ahiort | sed 's@\(.\)@\&\& /\1/ @g' && /a/ && /h/ && /i/ && /o/ && /r/ && /t/
We can now create a script named pangrams:
#!/bin/bash
expression=$(echo $2 | sed 's@\(.\)@\&\& /\1/ @g')
./spellingbee $1 $2 | awk "/$1/ $expression {print;}"
Run the script, and you’ll find that “ahiort” with a required “c” has two pangrams:
$ ./pangrams c ahiort chariot thoracic
Each pangram is worth an additional seven points. So use wc -l to count pangrams, then multiply the count by 7 using expr to calculate their points:
$ expr 7 '*' $(./pangrams c ahiort | wc -l) 14
Add these points to the previous total to get the true maximum possible score.
$ expr $(./spellingbee c ahiort | awk -f total-points.awk) \
+ $(expr 7 '*' $(./pangrams c ahiort | wc -l))
311
Challenge: Try to calculate your score from the guesses file including pangram points.
Generating hints
Each New York Times Spelling Bee puzzle comes with two kinds of hints. The first type is a grid that shows how many words have a certain first letter and length. It looks roughly like this:
4 5 6 7 8 9 ------------------ A: 1 3 3 2 - 1 C: 7 12 7 3 2 1 H: - 3 1 - - - I: 1 - - - - - R: 1 1 1 1 - - T: 2 3 2 1 1 -
So in this example, if you look at row H, column 5, you’ll see the value 3. It means the solution contains three words that begin with H and have length 5. List them with this command:
$ ./spellingbee c ahiort | awk '/^h/ && length($0) == 5' hatch hitch hooch
The following awk program generates the entire grid of hints.
# hints-grid.awk
BEGIN {
# Track the minimum and maximum word length found so far.
# Initialize them with values that are out of any practical range.
min=9999;
max=0;
}
{
# Grab and capitalize the first letter of the current word.
first_letter = toupper(substr($1,1,1));
# Calculate the word's length
len = length($1);
# Keep track of the current min and max word length.
min = (len < min) ? len : min;
max = (len > max) ? len : max;
# Maintain two arrays. "all_first_letters" tracks whether or not a
# given letter has appeared at the beginning of any word (1 = yes).
# "grid" is a two-dimensional array that records how many words with
# a given first letter and given length have been seen so far.
all_first_letters[first_letter] = 1;
grid[first_letter, len]++;
}
END {
# Print the table heading: all values between min and max.
printf(" ");
for (i = min; i <= max; i++) {
printf ("%3d", i);
}
print ""
# Print a nice long border. Probably too long.
print " ------------------"
# For each letter...
for (letter in all_first_letters) {
row = "";
# For each word length...
for (i = min; i <= max; i++) {
# Grab the number of words with this first letter & length
entry = grid[letter, i];
# Store either the number or a dash for zero
if (entry) {
row = row sprintf("%-3d", entry);
} else {
row = row sprintf("%-3s", "-")
}
}
# Print all rows in alphabetical order
printf "%c: %s\n", letter, row | "sort";
}
}
Pipe the output of spellingbee to this awk program to produce the hint grid for a given puzzle:
$ ./spellingbee c ahiort | awk -f hints-grid.awk
4 5 6 7 8 9
------------------------
A: 1 3 3 2 - 1
C: 7 12 7 3 2 1
H: - 3 1 - - -
I: 1 - - - - -
R: 1 1 1 1 - -
T: 2 3 2 1 1 -
The second type of hint shows how many words begin with two given letters. The hints are presented in a shorthand: two letters, a dash, and a number. For example, CA-10 means that 10 words begin with CA. Here’s a full set of hints for our puzzle:
AC-3 AR-4 AT-3 CA-10 CH-11 CI-2 CO-6 CR-3 HA-1 HI-1 HO-2 IT-1 RI-2 RO-2 TA-4 TH-2 TO-1 TR-2
You can isolate the first two letters of each solution word using the cut -c1-2 command, and then count the number of occurrences using sort and uniq -c:
$ ./spellingbee c ahiort | cut -c1-2 | sort | uniq -c 3 ac 4 ar 3 at 10 ca 11 ch 2 ci 6 co 3 cr 1 ha 1 hi 2 ho 1 it 2 ri 2 ro 4 ta 2 th 1 to 2 tr
Now, make the output look like the real hints in the New York Times game. Add this awk program that manipulates the previous results:
# hints-two-letters.awk
{
# Grab the first letter, capitalized
first_letter = toupper(substr($2,1,1));
# Produce the hint
formatted_hint = toupper($2) "-" $1
# Maintain an array of strings. Each element is a rows of hints.
# Append the current hint to the right row, indexed by first letter.
hints[first_letter] = hints[first_letter] formatted_hint " "
}
END {
# Print all hints
for (hint in hints) {
print hints[hint]
}
}
Then pipe the output of the previous pipeline to this awk program to produce properly formatted two-letter hints for a given puzzle:
$ ./spellingbee c ahiort | cut -c1-2 | sort | uniq -c | awk -f hints-two-letters.awk AC-3 AR-4 AT-3 CA-10 CH-11 CI-2 CO-6 CR-3 HA-1 HI-1 HO-2 IT-1 RI-2 RO-2 TA-4 TH-2 TO-1 TR-2
I hope you’ve had fun geeking out with me on spelling puzzles. Check out my book Efficient Linux at the Command Line to continue building your Linux command-line skills.